군집화 (Clustering)
2020. 8. 25. 00:47ㆍ캐리의 데이터 세상/캐리의 데이터 공부 기록
반응형
군집화와 분류 차이점을 이미지로 비교하고, 군집화의 활용 사례와 유의 사항, 문제점, 알고리즘에 대해 알아보겠습니다.
1. 군집화(Clustering)과 분류(Classification) 차이

- 분류 : y값이 있고, Supervised, 사전에 정의된 범주가 있으며(labeled), 그 데이터로부터 예측 모델 학습
- 군집화 : y값 없고, Unsupervised, 범주 없으며(unlabeled), 데이터에서 최적 그룹을 찾아가는 문제
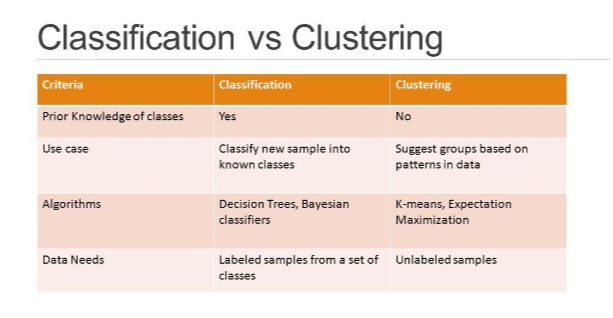
2. Clustering 활용 사례 :
- market segmentation
- social network analysis
- search result grouping
- medical imaging
- image segmentation anomaly detection
3. Clustering 수행 시 유의 사항:
- 어떤 거리 척도를 사용하여 유사도를 측정할 것인가?
- 어떤 군집화 알고리즘을 사용할 것인가?
- 어떻게 최적의 군집 수를 결정?
- 어떻게 군집화 결과를 측정/평가?
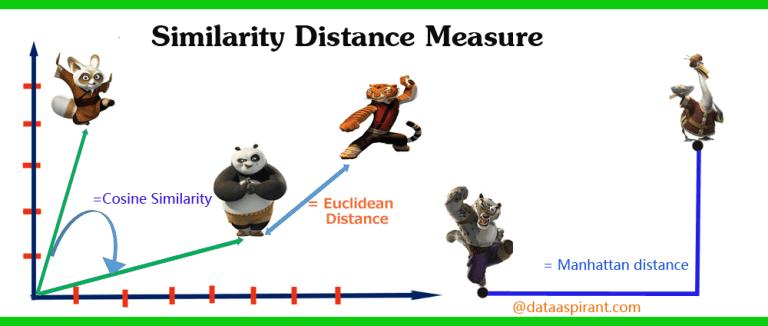
4. 유사성, 거리 척도 :
- Euclidean distance (유클리디안 거리)
- Manhattan distance (맨하탄 거리)
- Mahalanobis distance (마할라노비스 거리)
- Correlation distance (상관관계 거리)
5. 군집화 알고리즘 분류:
- Hierarchical Clustering (계층적 Tree 모형 이용, 개별 개체들 순차적-계층적 유사 개체 군집 통합, Dendrogram 시각화)
- Partitioning Methods (k-means, PAM, CLARA)
- Density-Based Clustering
- Model-based Clustering
- Fuzzy Clustering
6. 군집화 문제점 :
- 서로 다른 크기의 군집 잘 찾지 못함
- 서로 다른 밀도의 군집 잘 찾지 못함
- 지역적 패턴이 존재하는 군집 판별하기 어려움 (Geodesic distance 참조)
7. 최적의 군집 수 결정 문제 :
-Dunn, SSE, Silhouette 등. 이중 실루엣(군집간, 군집내 거리 둘 다 고려) 계수 활용하는 경우 많음
-참고 링크의 towardsdatascience 팁 읽어보기
References:
반응형
'캐리의 데이터 세상 > 캐리의 데이터 공부 기록' 카테고리의 다른 글
| Coursera 코세라 딥러닝 강의 듣기 (0) | 2020.09.07 |
|---|---|
| 데이콘 대회 참여하기 (1) | 2020.08.26 |
| 판다스 get_dummies (0) | 2020.08.25 |
| 랜덤 포레스트 (Random Forest) 정리 (0) | 2020.08.15 |
| 비전공자 머신러닝 혼자 공부하기 커리큘럼(feat.선형대수) (0) | 2020.08.13 |
| 머신러닝(Machine Learning) 분류 (0) | 2020.08.10 |
| Chart.js로 그래프 만들기 (0) | 2020.07.29 |