2021. 7. 23. 16:07ㆍ인공지능 교육/Orange
오렌지로 기계학습 모델을 직관적으로 구현하는 실습을 하고 있는 중인데요, 고등학교 인공지능 기초 교과서에서는 텍스트 코딩이 아닌 Orange로 기계학습 모델을 구현하면서 파라미터 튜닝과 알고리즘 별 특성에 대해 담고 있기에 각종 데이터셋을 활용해서 Orange로 어떤 결과를 만들어 낼 수 있는지 포스팅을 이어가 보겠습니다. 이번 글은 UCI 기계학습 저장소에서 스팸메일 데이터셋을 다운로드하여 데이터 전처리부터 시작합니다.
1. 데이터 수집 - 데이터셋 준비
UCI의 Machine Learning Repository에서 SMS Spam Collection Data Set을 다운 받습니다.
- 상단의 Download : Data Folder를 클릭하면 zip 파일로 다운 가능.
- 압축을 풀고 메모장으로 텍스트 파일을 열어줍니다
- 데이터 세트를 살펴보면 수집한 SMS 데이터들은 한 줄 정도의 단문 형태로, ham(정상), spam (스팸)으로 레이블로 구분된 비정형 데이터인 텍스트 데이터로 이뤄져 있습니다.

2. 데이터 탐색 - 데이터셋 입력 및 전처리, Train/Test 분리
모델 학습에 사용할 트레이닝 데이터셋을 만들어 보겠습니다.
- 메모장 메시지 전문을 ham과 spam 한 문장씩 txt 파일을 만들어 ham 폴더와 스팸 폴더로 분리해줍니다. 해당 데이터셋은 실제로는 스팸 메시지는 747개, ham(정상) 메시지는 4,825개로 구성되어 있지만 하나씩 다 분리하기엔 시간이 오래 걸리므로 어떻게 모델이 구현되는지 확인하기 위해 저는 ham 메시지 60개, spam 메시지 40개로 분리했습니다.
(1) ham00.txt 파일에 전문에서 하나씩 뽑아낸 레이블별 한문장 씩 넣어 줍니다.
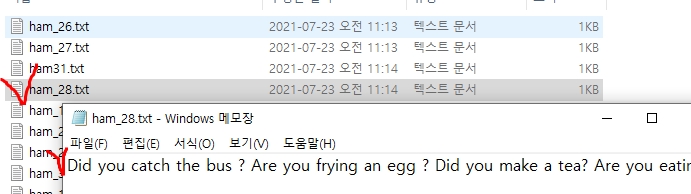
▼ spam_uci 상위폴더 안에 ham과 spam 폴더를 각각 만들어 레이블별 파일을 분리해서 넣었습니다.
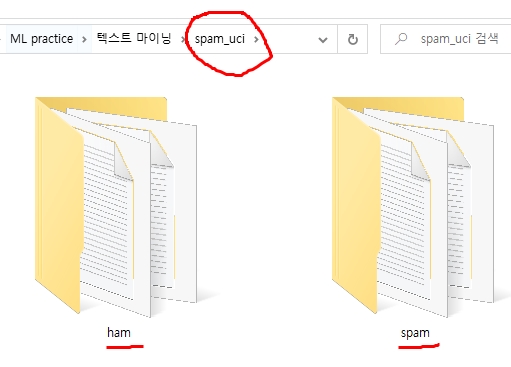
(2) Orange 새 파일 창에서 Text Mining -> Import Documents 위젯을 선택하고 데이터셋 상위폴더인 spam_uci 폴더를 선택해서 데이터셋을 import 합니다
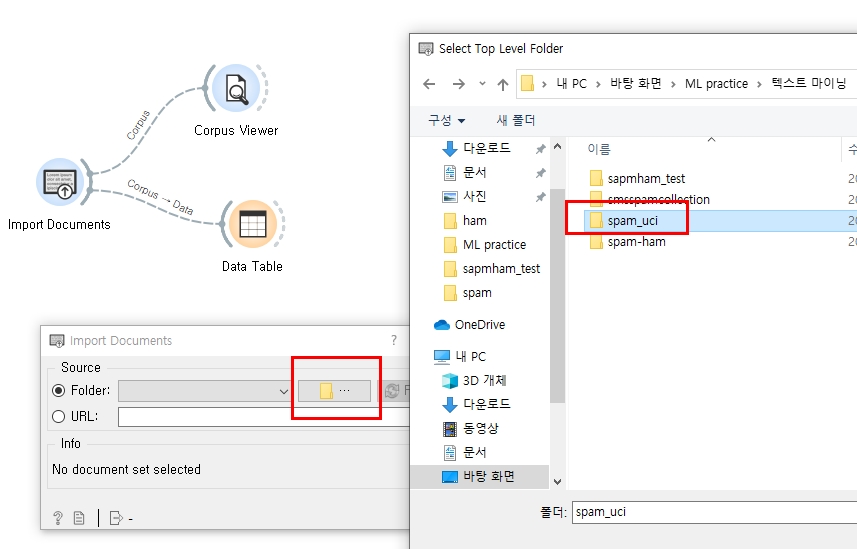
▼ ham과 spam 카테고리 2개가 잘 들어간 것을 확인할 수 있습니다. 100개의 documents가 정상적으로 import 되었습니다.
▼ Corpus Viewer 위젯과 Data Table 위젯을 각각 Import Documents와 연결해서 데이터가 잘 들어갔는지 다시 한번 시각적으로 확인할 수 있습니다.
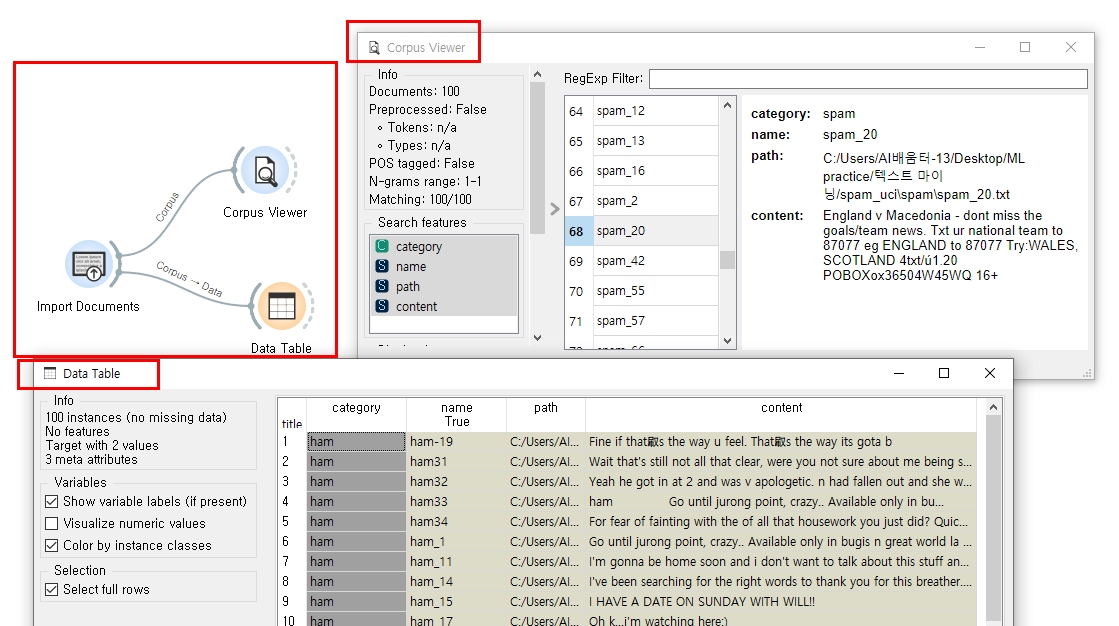
▼ 사용할 텍스트 마이닝 위젯
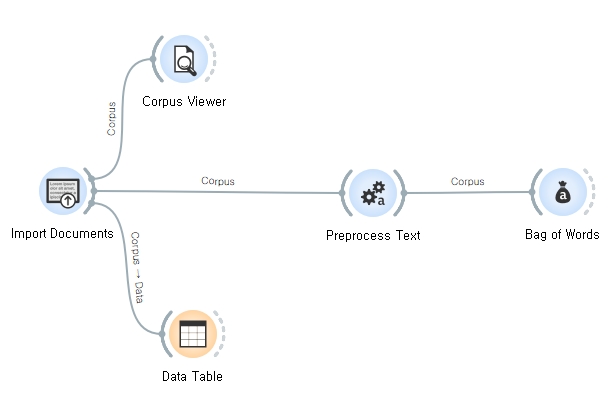
(3) 데이터 전처리를 위한 Preprocess Text 위젯과 단어 모음을 생성하는 Bag of Words 위젯을 연결해 줍니다.
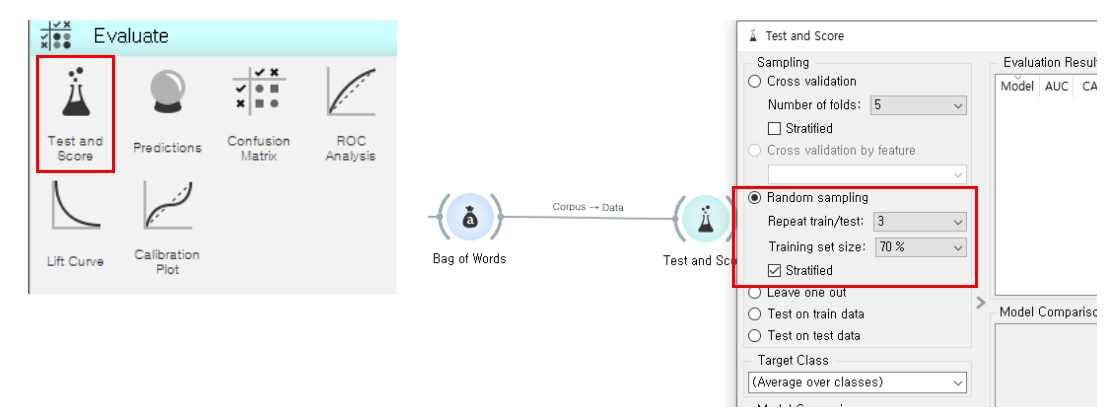
(4) Train / Test 데이터 분리하기
Evaluate에서 Test and Score 위젯을 가져와 연결합니다. 여러 샘플링 옵션 중에서 Random sampling을 선택하고 Training set size를 70%로 정했습니다. (데이터 크기에 따라 조정해도 무방) 전체 100개의 데이터를 입력했으니 70개는 Training 데이터로 사용되고 30개는 Test 데이터로 사용됩니다.
3. 모델링 및 성능 평가
앞서 분리한 Train 데이터를 사용하여 분류 모델을 학습시키고 Test 데이터를 통해 성능을 확인해 보겠습니다. 분류 모델 중에서 Logistic Regression(로지스틱 회귀)와 Neural Network(신경망) 위젯을 선택 후 연결해서 학습을 시킵니다. 학습 성능을 확인하기 위해서 Evaluate의 Confusion Matrix 위젯을 함께 연결합니다. 샘플링 설정 시에는 아무것도 보이지 않았던 Evaluation Result 창에서 모델 성능 평가지표를 함께 확인할 수 있습니다.
(1) 모델링 및 성능평가 위젯 연결
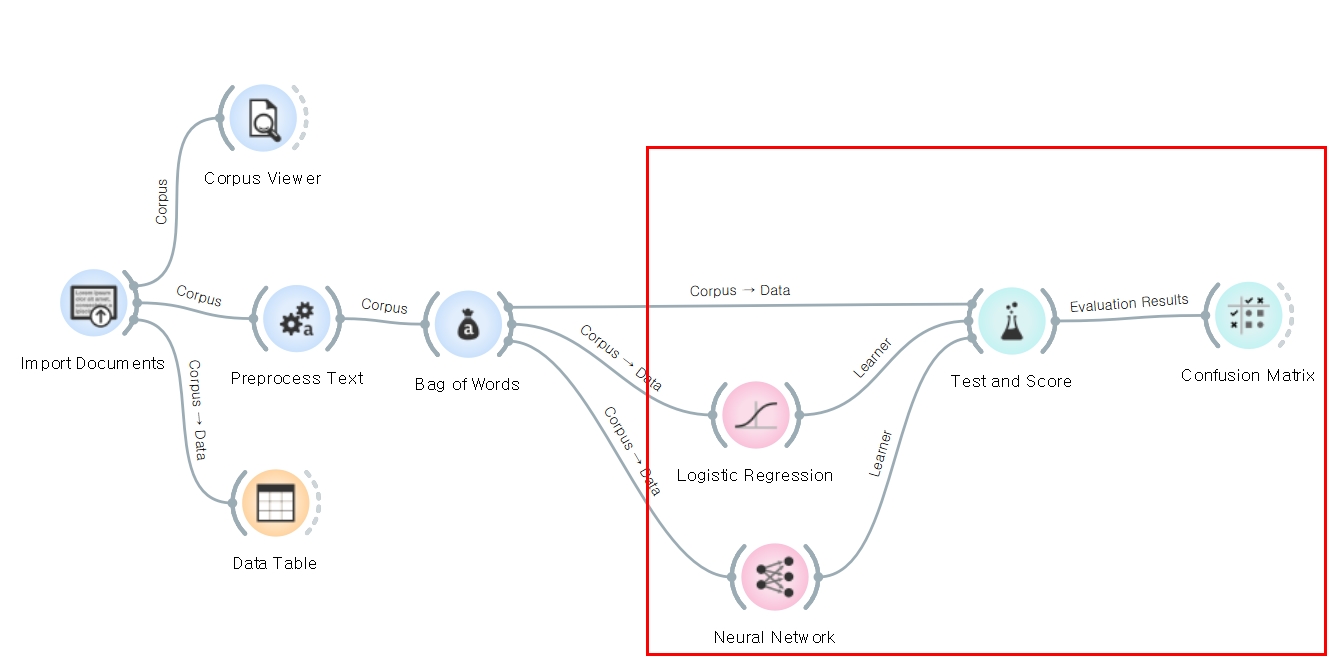
각각의 모델 위젯을 눌러보면 아래와 같이 회귀 모델에서 가중치를 제한함으로써 규제를 가할 때 쓰는 Ridge(릿지 회귀), Lasso(라쏘 회귀)를 선택할 수 있습니다. 또한 NN에서는 하이퍼 파라미터를 조정할 수 있습니다. (은닉층 뉴런 개수, 활성화 함수, 옵티마이저(Adam, SGD 등))
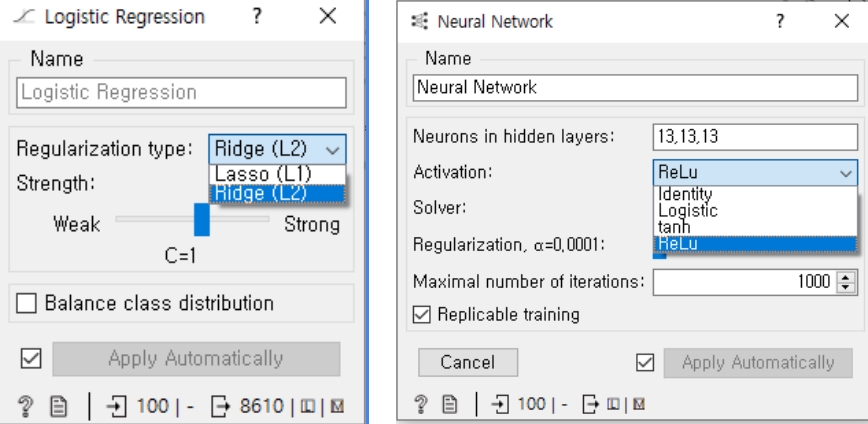
(2) 모델 성능 평가 결과 비교
아래 Confusion Matrix에서 스팸 메시지를 ham(정상)으로 잘못 분류한 데이터가 NN은 17개, 로지스틱 회귀는 19개로 NN의 성능이 좀 더 나은 것을 확인할 수 있습니다.
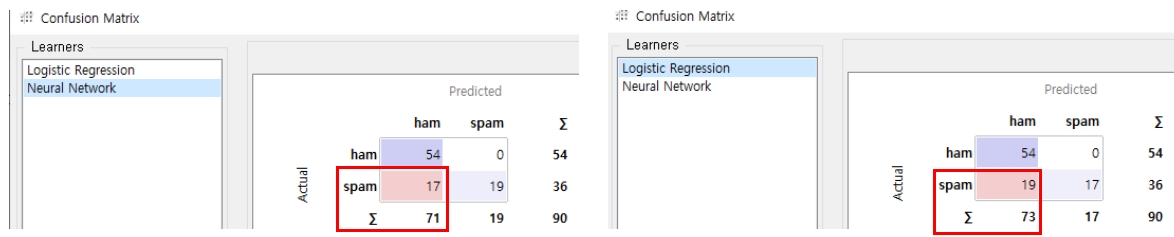
Test and Score위젯을 눌러보면 Evaluation Results에 두 개의 모델별 각종 평가지표에 대한 수치를 확인할 수 있는데요, Precision(정밀도)와 CA(분류 정확도) 또한 NN이 나은 것을 확인할 수 있습니다.
▼ 참고글 : 정밀도, 재현율 F1 스코어 구하는 방법 등 설명
오차 행렬(confusion matrix)로 분류 성능 평가
4. 모델 활용 - 새로운 데이터로 예측해보기
학습한 데이터 외에 새로운 메시지를 입력했을 때도 스팸인지 정상인지 분류해 낼 수 있는지 확인해 보겠습니다. 먼저 아까 만든 spam-uci 폴더가 아닌 다른 폴더에 신규 테스트 파일을 넣어봅니다. 저는 다운로드한 전문에서 학습에 쓰이지 않았던 다른 문장들을 ham 2개, spam 2개 텍스트 파일로 각각 저장했습니다. 이때는 spam인지 ham인지 따로 폴더를 만들 필요 없이 한 폴더에 다 담아줍니다.(비교를 위해 파일명에는 어떤 것이 spam, ham인지 식별할 수는 있어야 겟죠~)
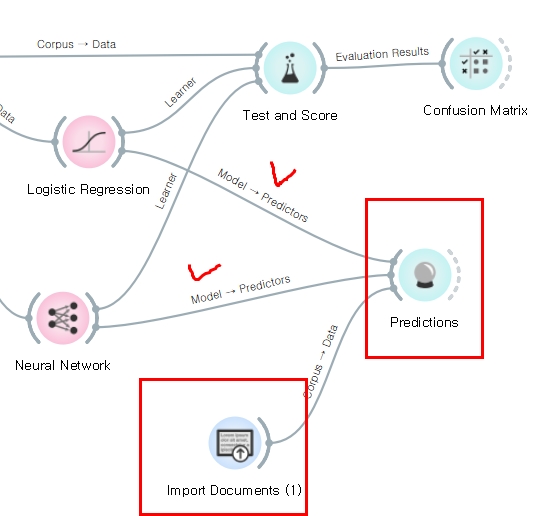
(1) 예측 수행을 위한 위젯은 다음과 같이 연결합니다.
예측에도 NN과 Logistic Regression의 성능이 차이가 있는지 확인하기 위해 둘 다 연결해 보겠습니다
- Predictions 위젯을 Evaluate 목록에서 선택한 후 앞서 만들어 놓은 모델 2개에 연결
- 새로운 Import Documents 위젯 선택 후 만들어 놓은 신규 테스트 폴더 선택, import
- Import 한 데이터와 Predictions를 연결
- Predictions 위젯을 더블클릭하여 분류 결과를 확인합니다
(2) 예측 결과 비교
Predictions를 눌러보면 각 모델별 분류 결과를 확인할 수 있습니다. 테스트 데이터가 몇 개 안되다 보니 ham과 spam으로 정확하게 분류해 냈습니다. 데이터별로는 모델별로 성능 차이가 있음을 아래 확률 수치를 통해 확인할 수 있습니다. 어떤 데이터는 NN가 스팸 데이터를 스팸일 확률이 NN보다 높다고 더 잘 판단했으며 그 반대도 존재.

편의상 학습 데이터가 100개밖에 안되고 대부분 하이퍼 파라미터도 디폴트 값을 사용했는데요, 어떤 식으로 flow가 구성되는지를 확인하기 위한 간단 버전임을 감안해 주시고, 인공지능 모델링 개념을 익히는 데는 시각적으로 아주 좋은 플랫폼인 것 같습니다.
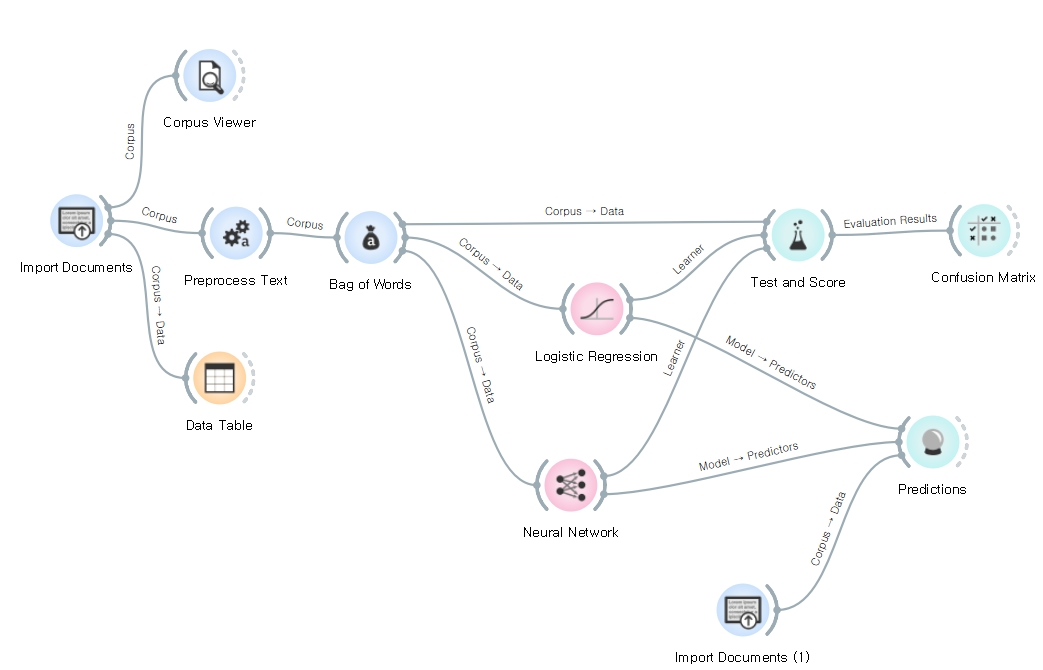
그럼 전체 flow를 볼 수 있는 위젯 연결 이미지 아래와 같이 정리하며, 이미지 데이터셋 활용한 모델도 다음 포스팅에서 다뤄보겠습니다.
오렌지를 활용한 Text Mining 상세 안내는 Orange 공식 홈페이지 Text Mining 섹션에서 확인할 수 있습니다. 참고로 한글 분석은 지원되지 않습니다. 영어 데이터를 활용해야!
'인공지능 교육 > Orange' 카테고리의 다른 글
| Orange 데이터 마이닝 자료 모음 (0) | 2021.08.23 |
|---|